Housing prices reflect structural, social, and economic forces. This early machine learning project explores how different modeling choices capture—or obscure—those forces, and what that means for interpretability and trust.
Project Links
This project marks an early milestone in my machine learning journey. Built during an intense bootcamp, it became a valuable reference point for my own learning trajectory. Looking back, it’s helped me clarify the tradeoffs between model complexity, interpretability, and real-world usefulness—insights I now apply more deliberately in later projects. A remodel is on the horizon.
Project Overview
The emphasis here is less on predictive power and more on understanding how different models encode assumptions about value.
I began with exploratory data analysis to investigate key factors affecting home values, address missing data, and prepare features for modeling. Then I built two predictive models: a neural network using TensorFlow and Keras, and a random forest to offer a more interpretable baseline.
After hyperparameter tuning, I compared performance using residual plots, scatter plots, and training loss visualizations. Each model offered different strengths in handling complexity, variance, and interpretability.
While the neural net was arguably overkill for this dataset, the project was a vital hands-on introduction to machine learning pipelines, model evaluation, and the tradeoffs between black-box and tree-based methods.
Gallery
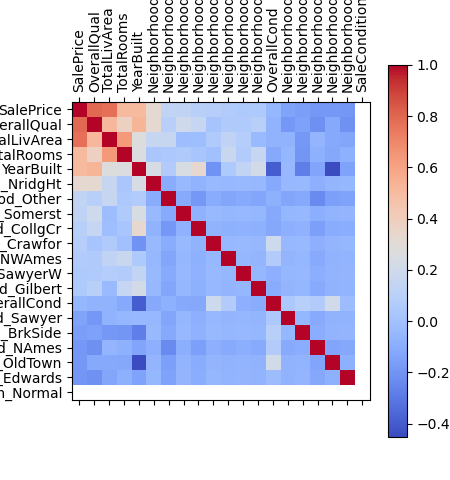 Correlation heatmap: Sale price is most strongly linked to
overall quality, total living area, number of rooms, and year
built.
Correlation heatmap: Sale price is most strongly linked to
overall quality, total living area, number of rooms, and year
built.
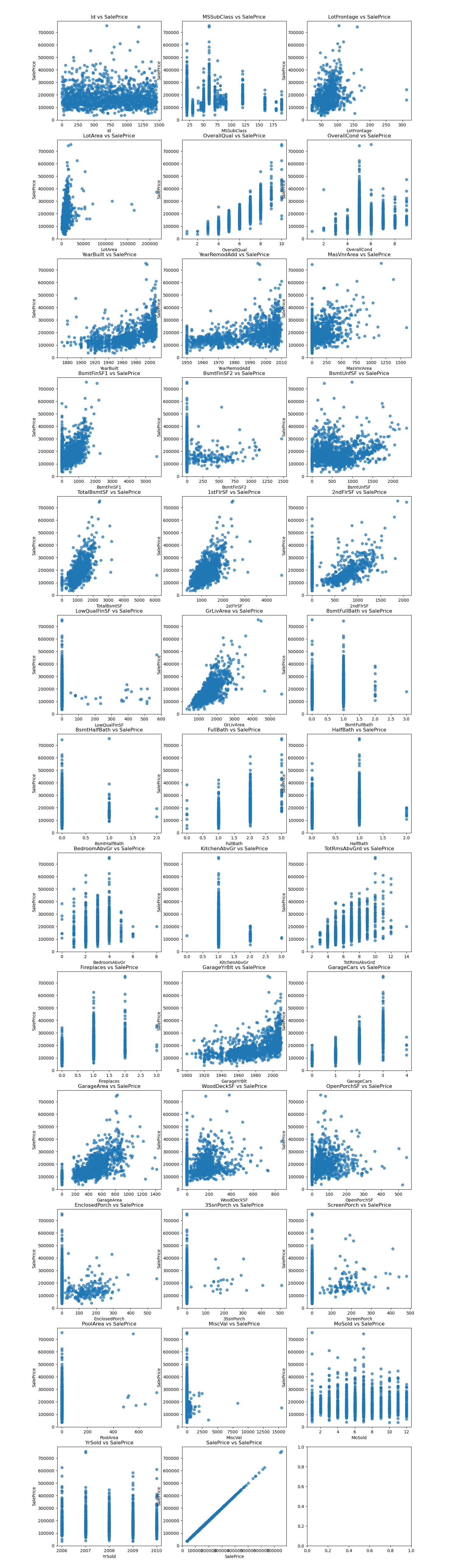 Scatter plots: Exploring how a wide range of features relate to
sales price, highlighting the dataset’s rich potential for machine
learning.
Scatter plots: Exploring how a wide range of features relate to
sales price, highlighting the dataset’s rich potential for machine
learning.
References
Dataset from the Kaggle House Prices: Advanced Regression Techniques competition.